
Spatial Pyramid Pooling 空间金字塔池化
前言
为什么CNN需要一个固定的输入尺寸?对于一个CNN模型,通常需要两个部分:第一部分由卷积层堆积而成,用于提取图像的特征。第二部分通常会连接一个全连接层,将之前卷积层提取到的特征信息进行整合,对信息进行分类、回归,最后得到网络输出。
卷积层通过滑动窗口的方式对输入的图像进行特征提取,输出一组特征图。对于一个全连接网络来说,它的输入和输出层的神经元个数是固定的,不同尺寸的图像通过一系列卷积层之后,得到的特征图的大小是不同的,那么将其一维展平后输入到全连接层的输入维度也就不同,所以为了适应全连接网络,不同尺寸的图像输入到网络之前需要进行resize或者crop处理。如果对图像进行resize,输入图像的比例改变了,原本细长的物体可能会变得粗矮,这种变化可能不利于网络对图像特征的理解。此外,从一个大尺寸的图像resize到一个小尺寸的图像也会造成某些细节的丢失,这种损失对于分类任务中可能没有那么明显,但是在小目标检测中,或者一些细粒度较高的视觉任务当中,可能会有更加明显的影响。crop操作带来的是图像信息的直接丢失,使得目标不完整,必定会影响网络的性能。

SSP结构
SPP受到SPM的启发,设计出一种类似的结构解决这一问题。
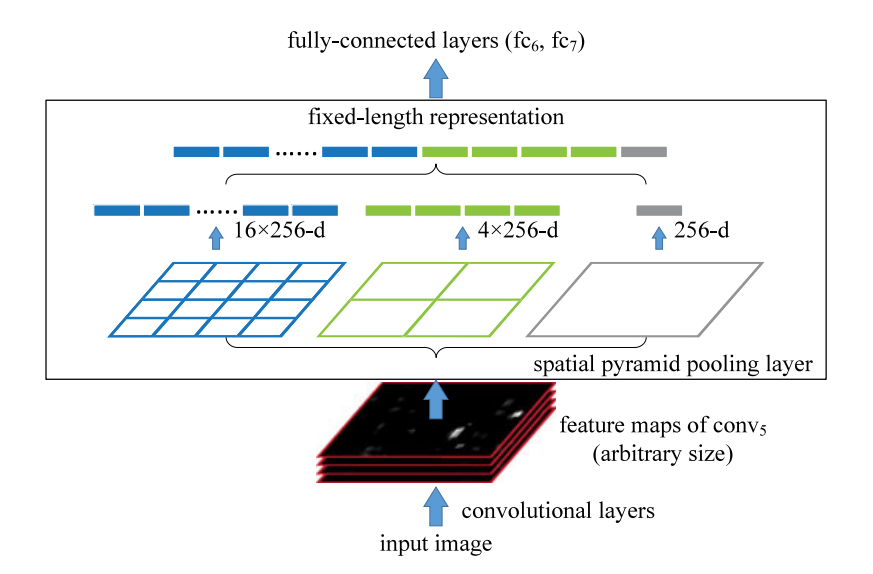
SPP layer将特征图分为nxn的网格,对特征图的每一个网格进行Max pooling后将其拼接成一个一维的vector,这样不论输入的特征图的大小和比例如何,最后都可以将其变成一个固定长度的vector。将不同尺度的网格生成的vector进行拼接后最终就可以把任意大小的特征图变成固定长度,送入全连接网络中。
相比于之前对最后一层特征图进行展平后送入全连接网络,SPP可以融合多尺度的特征信息。因为最后生成的vector不再是只来自某一层的feature map,而是对feature map在不同的比例下进行max pooling后拼接而成。这一变化会使网络拥有不同感受野下的特征信息。
多尺度的训练
解决固定输入尺寸的问题,网络就可以学习不同尺寸的图片输入。在训练时可以分轮次将不同尺寸的图片输入到网络中。由于不同尺寸的图像在提取特征时特征大小发生了改变,反映到特征图中的特征信息也可能会有变化。通过对不同尺度下图像特征的学习,有利于网络理解特征,对网络的精度和鲁棒性可能会有所提升。

