
深度学习笔记-Faster RCNN
R-CNN
FasterRCNN实际上是由R-CNN->Fast R-CNN->Faster R-CNN不断优化而来的。R-CNN是深度学习进行目标检测的开山之作。
检测流程
- 使用Selective Search方法在一张图像生成1k~2k个候选区域
- 对每个候选区域,使用深度网络提取特征
- 特征送入每一类的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
1、候选区域生成
使用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域进行合并,得到一个层次化的区域结构,而这些结构就包含可能需要检测的物体。

2、特征提取
将2000个候选区域缩放到227x227,将候选区域输入到事先训练好的AlexNet分类网络获取4096维的特征得到2000x4096维矩阵。
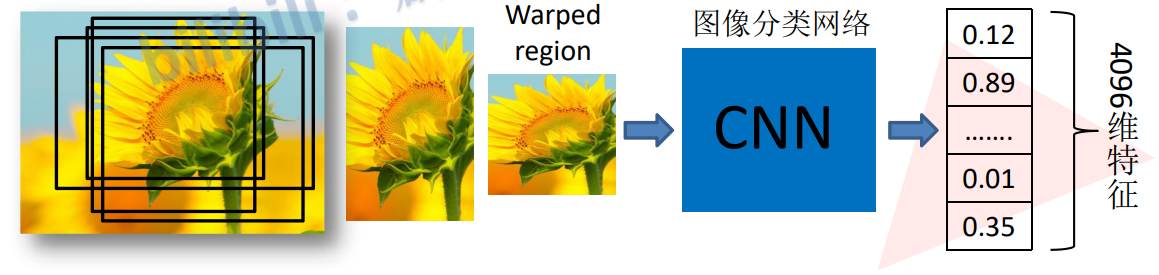
3、判定类别
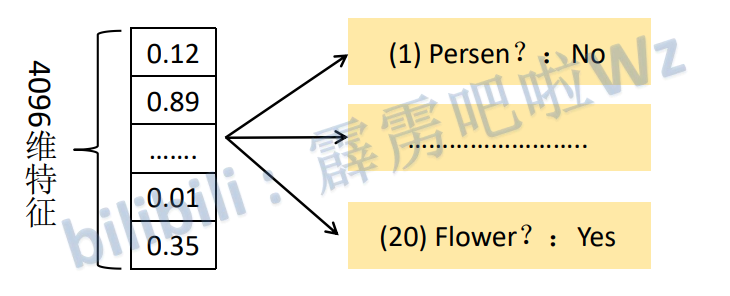
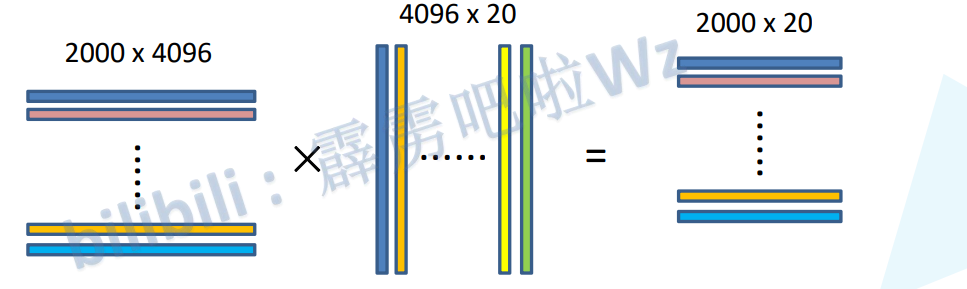
将2000x4096维特征矩阵与20个SVM分类器组成的4096x20维权值矩阵相乘,获得2000x20维矩阵,表示每个建议框是某个目标类别的得分。分别对上述2000x20维矩阵中每一列即每类进行非极大值抑制提出重叠建议框,得到该类得分最高的一些建议框。
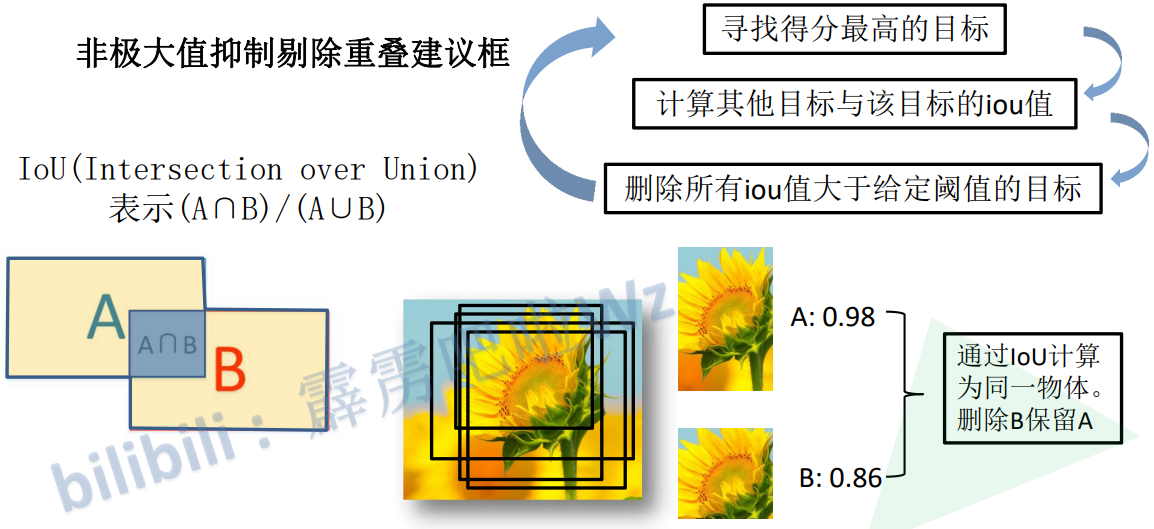
非极大值抑制剔除重叠建议框
4、修正候选框位置
对NMS处理后剩余的建议框进一步筛选。分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别修正后得分最高的bounding box。

RCNN存在问题
测试速度慢
测试一张图片约53s(CPU)。用Selective Search算法 提取候选框用时约2秒,一张图像内候选框之间存在大 量重叠,提取特征操作冗余。
训练速度慢
训练所需空间大
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框 提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07 训练集上的5k图像上提取的特征需要数百GB的存储空间。
Fast R-CNN
检测流程
一张图像生成1K~2K个候选区域(使用Selective Search方法)
将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
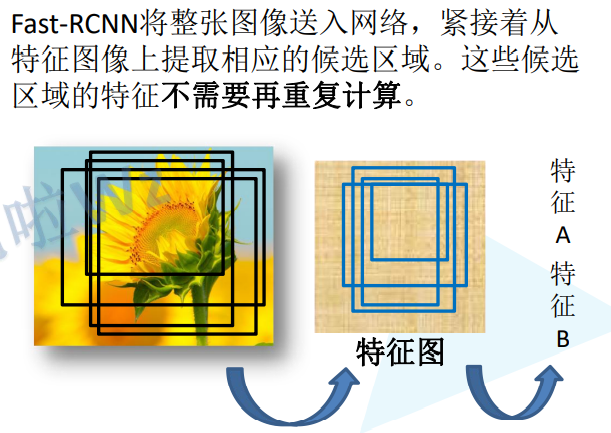
将每个特征矩阵通过ROI(Region of Interest) pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
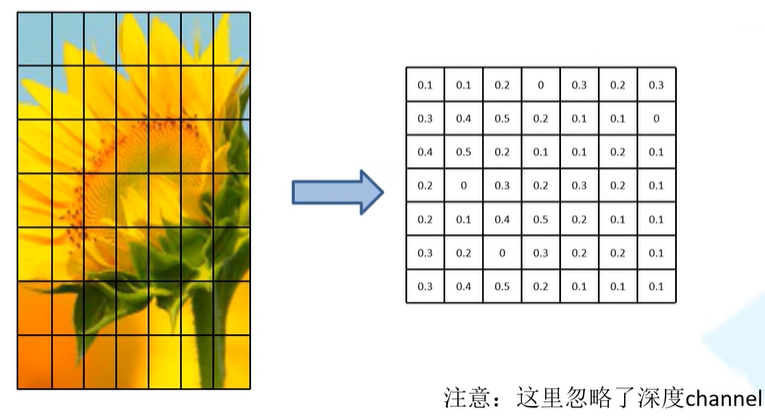
ROI Pooling 层将特征图通过7x7网格进行划分,对每一个网格执行最大池化操作,不论输入图像尺寸多少,最终都可以生成一个7x7的矩阵。
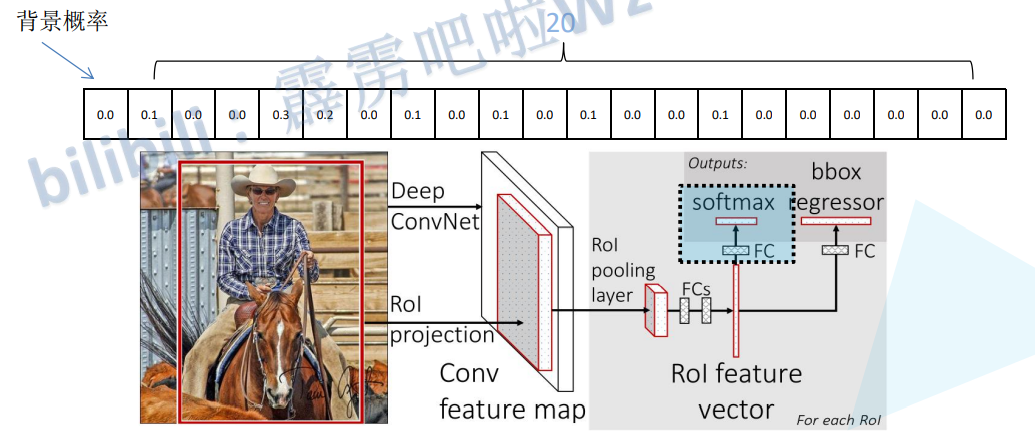
分类器输出N+1个类别的概率(检测目标类别+背景)
边界框回归器输出对应N+1个类别的候选边界框回归参数(d
x,dy,dw,d),共(N+1)*4个节点
Multi-task loss

- p是分类器预测的softmax概率分布
- u对应目标真实类别标签
- t^u^对应边界框回归器预测的对应类别u的回归参数(t^u^
x,t^u^y,t^u^w,t^u^h) - v对应真实目标的边界框回归参数(v
x,vy,vw,vh)
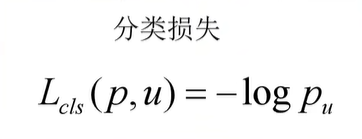
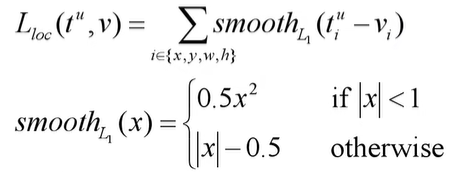
Faster R-CNN
检测流程
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图, 接着将特征图展平通过一系列全连接层得到预测结果
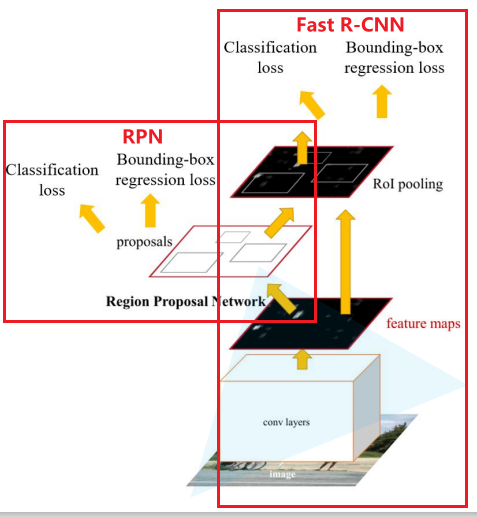
由上图我们可以看到,FasterRCNN实际上由Fast RCNN + RPN组成,所以Faster RCNN的关键在于RPN。
RPN
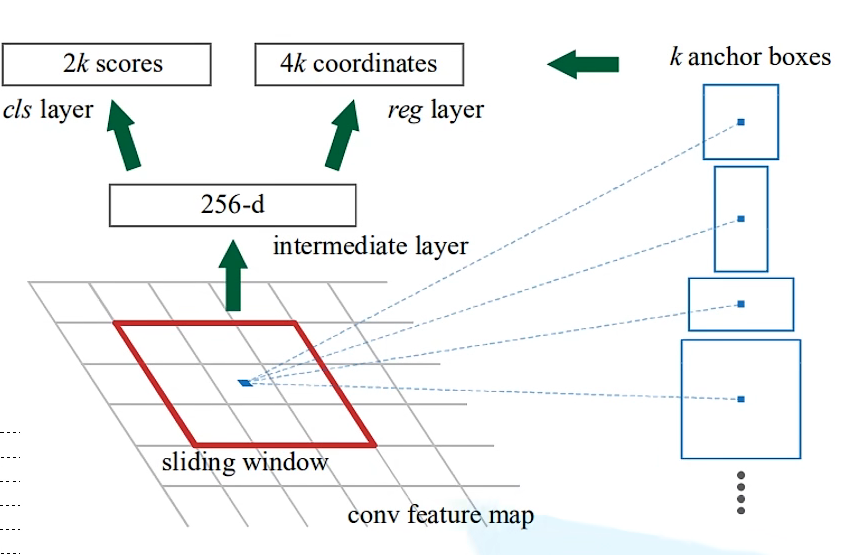
使用滑动窗口在特征图上滑动生成一个向量,将向量分别输入用于分类和监测边界框的全连接层得到2k个目标的分类概率和4k个边界框参数。
对于每一个滑动窗口,首先将中心点在特征图的坐标乘缩放比(原图宽/高除以特征图宽/高)计算出窗口中心点在原图像的位置,然后根据原图中心点位置生成k个anchor。
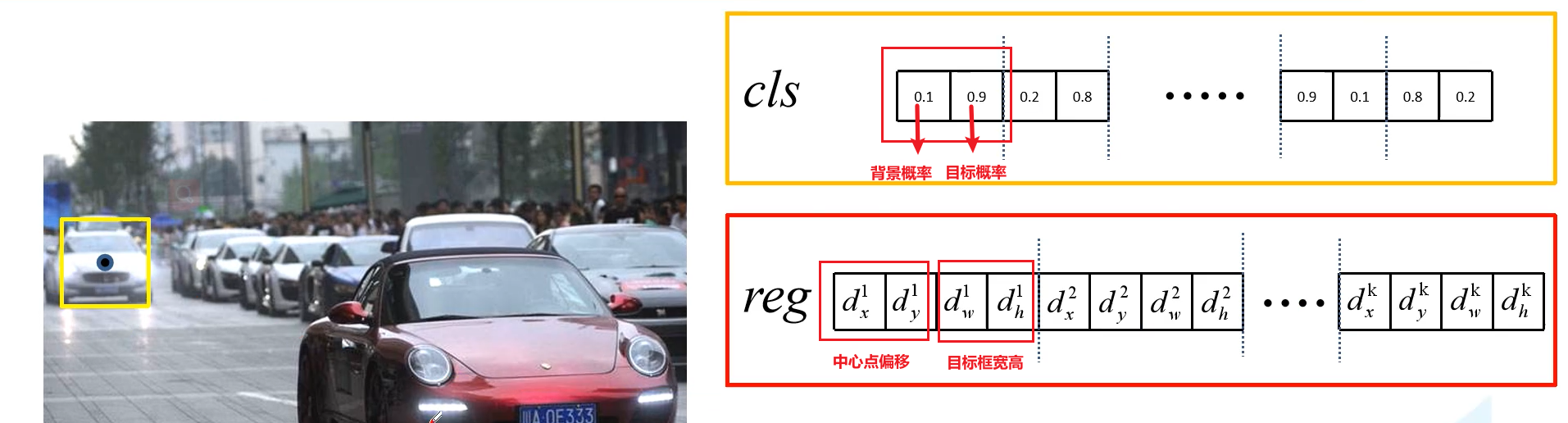
对于分类参数,两个为一组分别为背景的概率以及目标概率;对于回归参数,四个为一组,分别为anchor中心点x,y偏移和宽高。
对于一张1000x600x3的图像,大约有 60x40x9(20k)个anchor,忽略跨越边界的 anchor以后,剩下约6k个anchor。对于RPN 生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU 设为0.7,这样每张图片只剩2k个候选框。
训练数据采样
从样本中随机采样256个anchor,其中正负样本的比例为1:1,若正样本数不足达到1:1比例时,由负样本进行填充。
- 正样本:1)anchor 与某个 gound-truth box 有最大的IoU 2)anchor 与 gound-truth box 重叠超过70%
- 负样本:与所有 gound-truth box 的IoU值小于0.3
RPN Multi-task loss

分类损失
原论文中分类损失函数采用Softmax Cross Entropy,而不是Binary Cross Entropy,因为在分类层输出参数是包括目标概率和背景概率,实际是两个参数。在Pytorch的实现中采用的是Binary Cross Entropy,这样可以减少
边界框回归损失
边界框回归损失采用Smooth
L~~1进行计算。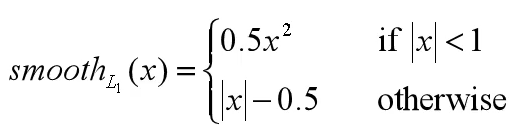
训练方式
目前使用Faster R-CNN时一般采用RPN Loss + Fast R-CNN的联合训练方法,但原论文分别训练RPN和Fast R-CNN。
(1)利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数。
(2)固定RPN网络独有的卷积层以及全连接层参数,再利用 ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN 网络生成的目标建议框去训练Fast RCNN网络参数。
(3)固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN 网络独有的卷积层以及全连接层参数。
(4)同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全 连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
笔记根据B站UP主霹雳吧啦Wz视频合集【深度学习-目标检测篇】学习整理

