
深度学习笔记-HRNet
简介
HRNet是由中科大与微软亚洲研究院共同提出,发表于CVPR2019,论文名为Deep High-Resolution Representation Learning for Human Pose Estimation。论文提出了一种针对类似于人体姿态检测这种高分辨率场景下的视觉任务的网络结构。
在此之前,主流的网络结构大多都是将分类网络作为backbone,进行特征提取,形成低分辨率的特征图,再通过上采样的方式将分辨率提高。这种方法对于高分辨率任务来说,会丢失大量原有的高分辨率信息,从而降低模型效果。
HRNet提出了一种并行的网络架构,由主分支始终保持高分辨率的特征,随后通过下采样并行加入低分辨率的分支以获取更大感受野下的抽象特征,然后将高分辨率与低分辨率的信息相互交换,使得主分支能得到更大感受野下的特征信息,同时低分辨率层也能获得细节特征。最后由高分辨率的分支输出最后的学习结果,也就是说引入的低分辨率分支的目的不再是为了特征的融合,而是为了让主分支在关注局部特征的同时也能关注全局信息。
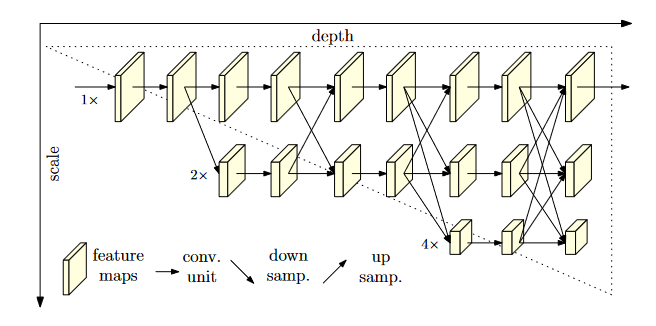
网络结构
网络的模型结构较为简单,主要采用与ResNet中类似的bottleneck残差单元进行特征提取,每一平行分支不会改变特征图大小,只有通道数的调整。

不同尺寸特征之间的信息交换通过下采样与上采样进行add。
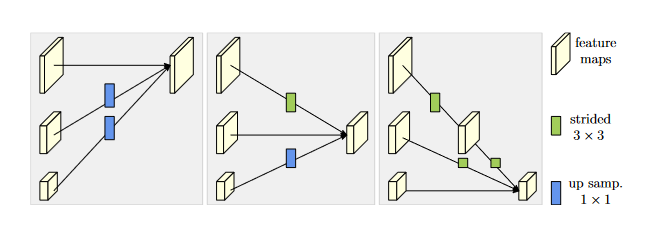
下采样采用一个3x3的卷积核进行卷积,使特征图变为原来的二分之一。若将特征图下采样为原来的1/4或1/8只需要叠加两个或者三个3x3 stride为2的卷积操作。
上采样操作采用线性插值算法使低维特征图进行2x、4x、8x的扩大。
HRNet最后输出的是一个通道数为17的特征图,对应人体17个关节点的热力图。
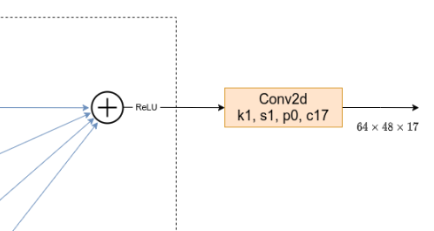
需要注意的是,对于人体关键点检测任务来说,在对输入图像进行resize操作时需要保持原图的宽高比,使图像在宽高上不会被缩放变形,使关键点的实际坐标相对偏移。
参考资料
- bilibili-霹雳吧啦Wz 【HRNet网络详解】
- Sun K, Xiao B, Liu D, et al. Deep high-resolution representation learning for human pose estimation



