
深度学习笔记-卷积神经网络基础(2)
误差的计算
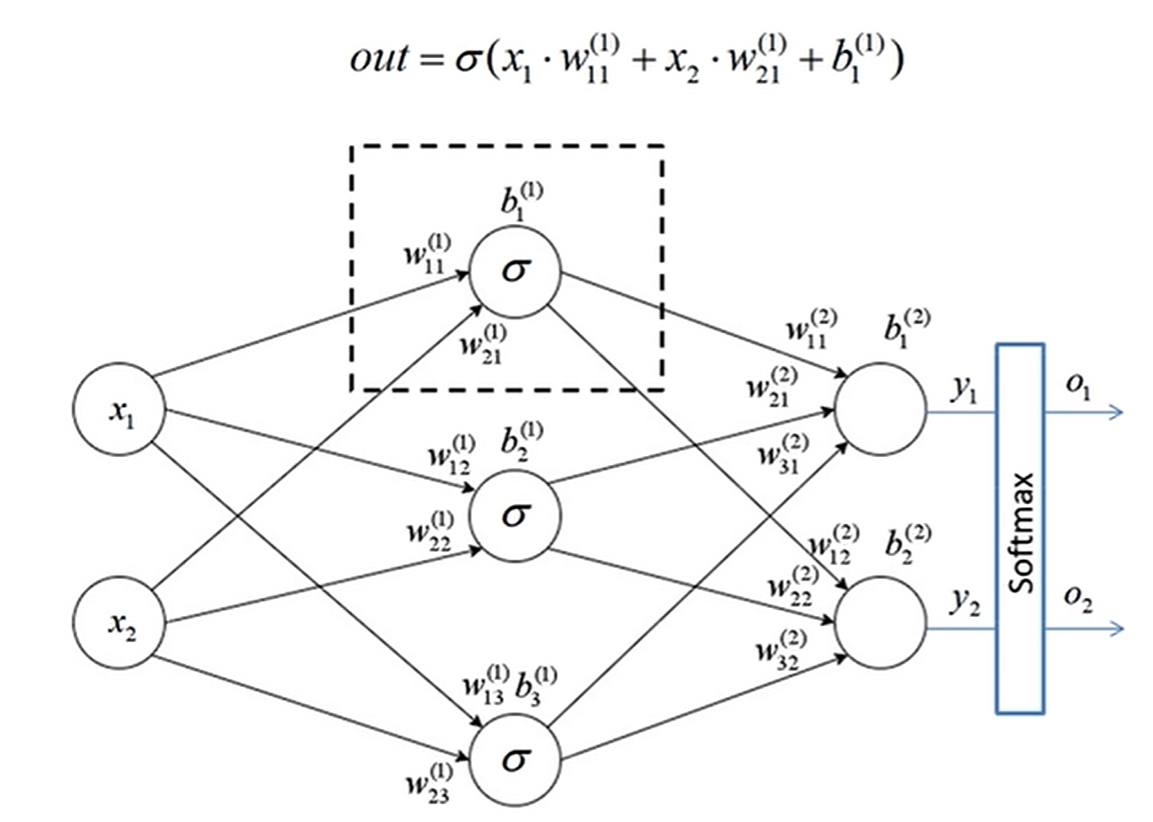

softmax
为了使输出满足概率分布,经过 softmax 处理后所有输出节点概率和为 1
表达式
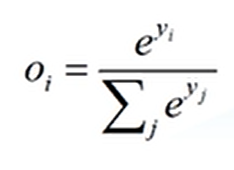
交叉熵损失

二者的区别:
使用 softmax 输出,输出值的概率和为 1,一个输入 x 要么是属于 A 类要么是属于 B 类要么是属于 C 类;
使用 sigmoid 输出,输入 x 可能即属于 A 类也属于 B 类,或者既不属于 A 类也不属于 B 类,
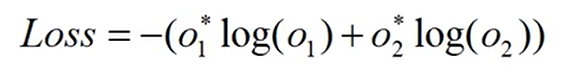
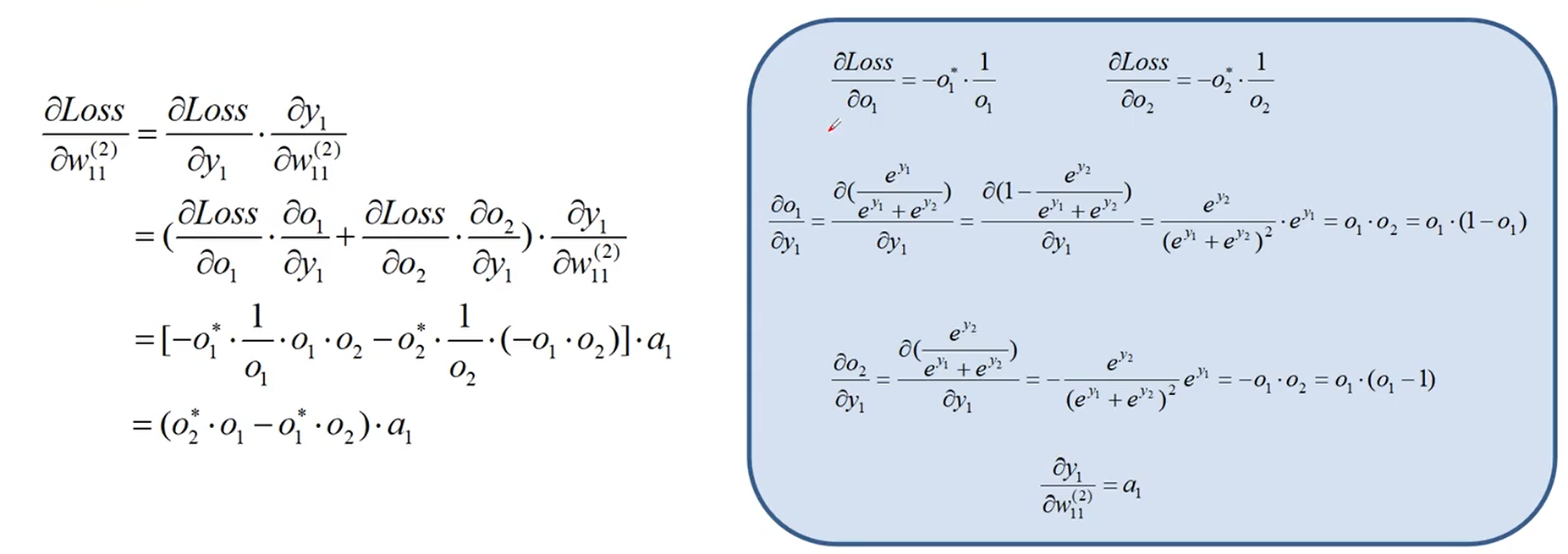
误差的反向传播
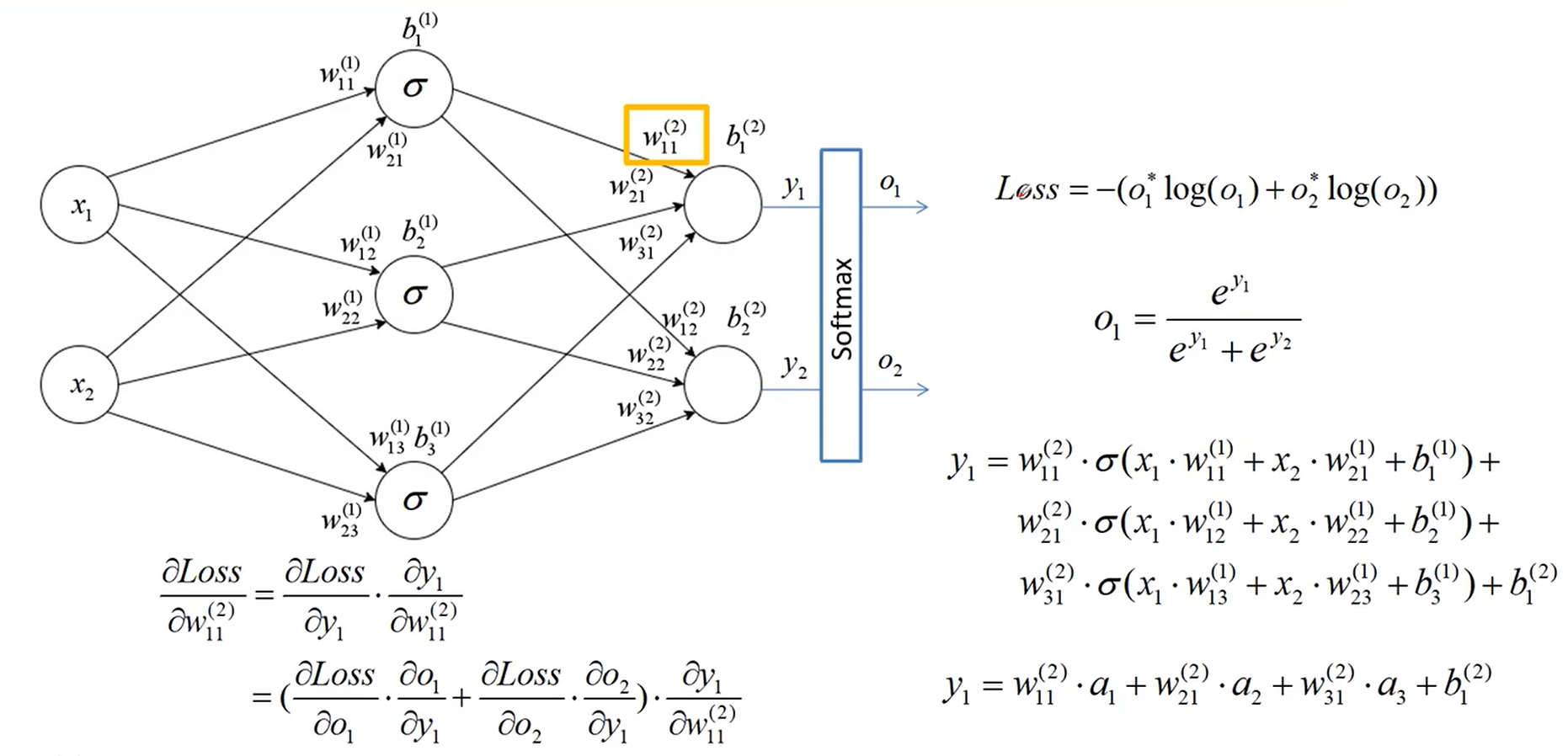
利用链式求导法则,将 Loss 对 W11的偏导数逐步展开求解
权重的更新

- 新权重 = 旧权重-学习率*梯度(Loss 对 W
11的偏导数)
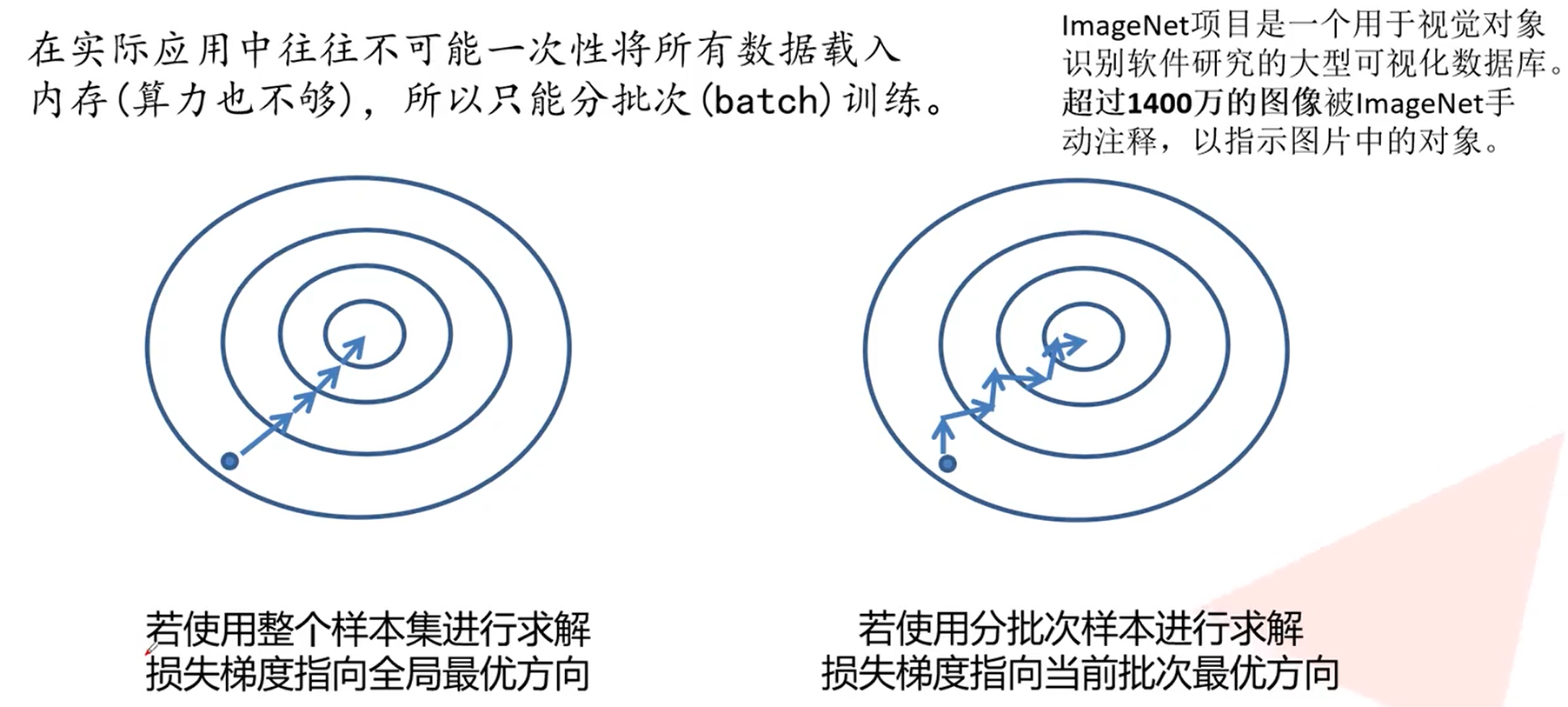
SGD 优化器
- W
t+1= Wt - α·g(Wt) - 缺点:1、易受样本噪声影响 2、可能陷入局部最优解
SGD + Momentum 优化器
V
t= η·Vt-1+ α·g(Wt)W
t+1= Wt- Vtη 为动量系数,一般为 0.9
Adagrad 优化器(自适应学习率)
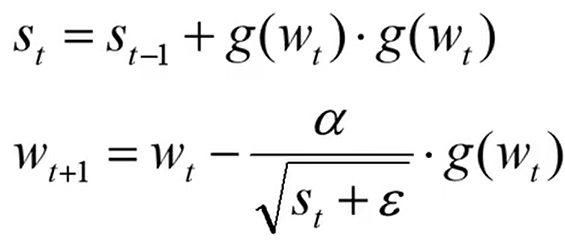

- 学习率下降太块可能还没收敛就停止训练
RMSProp 优化器(自适应学习率)
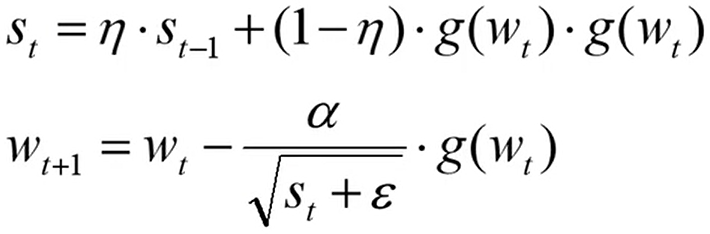

Adam 优化器(自适应学习率)
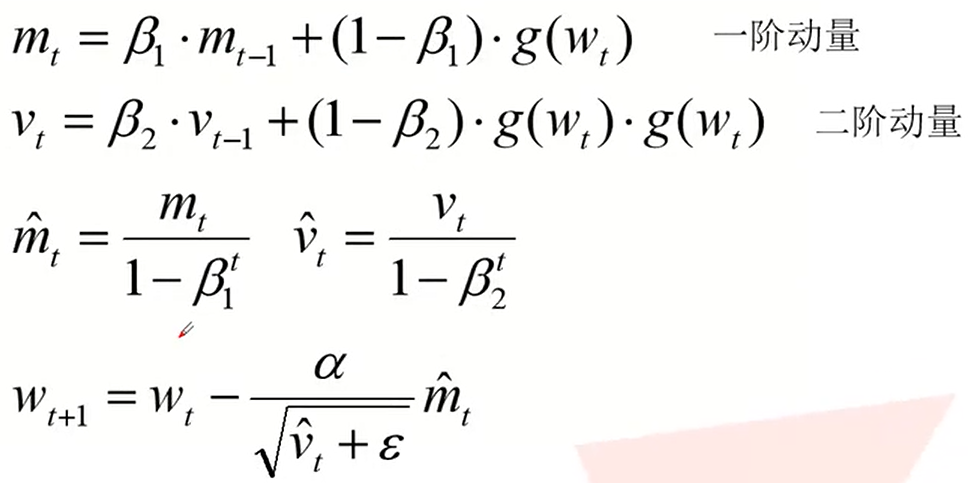

笔记根据B站UP主霹雳吧啦Wz视频合集【深度学习-图像分类篇章】学习整理

喜欢这篇的人也看了


评论
匿名评论
✅ 你无需删除空行,直接评论以获取最佳展示效果
