
网络结构
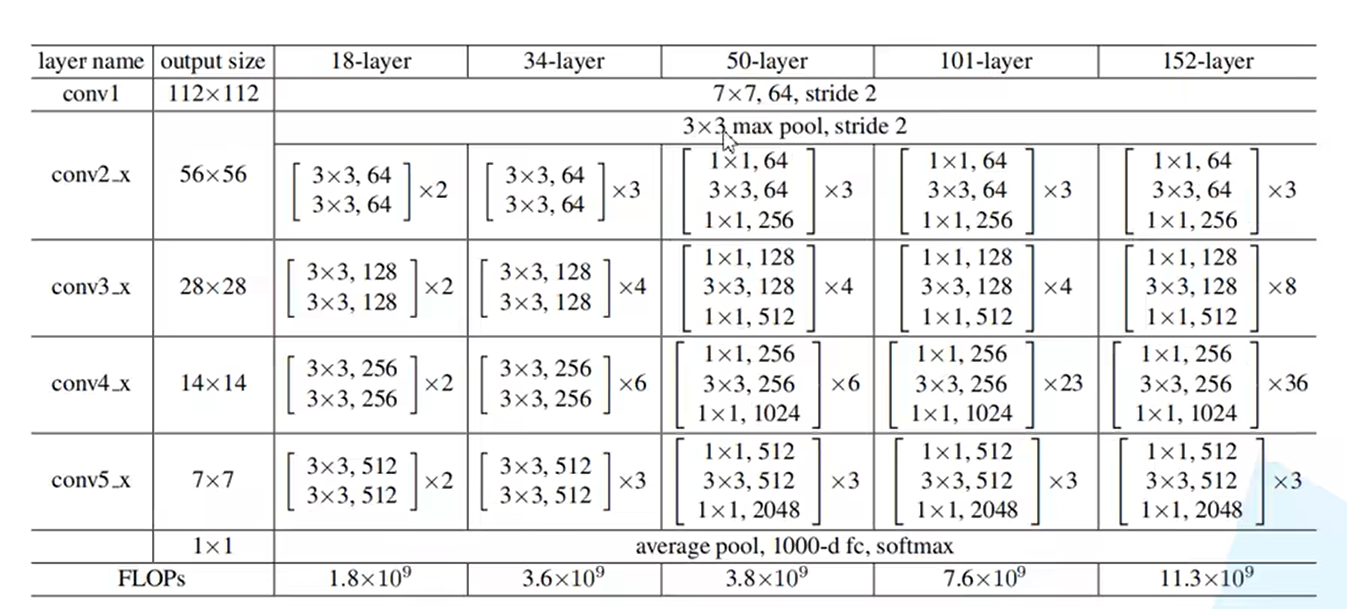
- 超深的网络结构
- 提出了residual模块
- 使用Batch Normalization
从直观印象来讲,深层卷积神经网络往往要比浅层网络的表现要更好。但随着网络层数加深,梯度消失或梯度爆炸问题会越来越明显。即使通过数据标准化、权重初始化以及Batch Normalization方法解决了梯度消失和梯度爆炸问题,神经网络依然存在退化问题,即随着层数的加深,神经网络的表现也会变差。
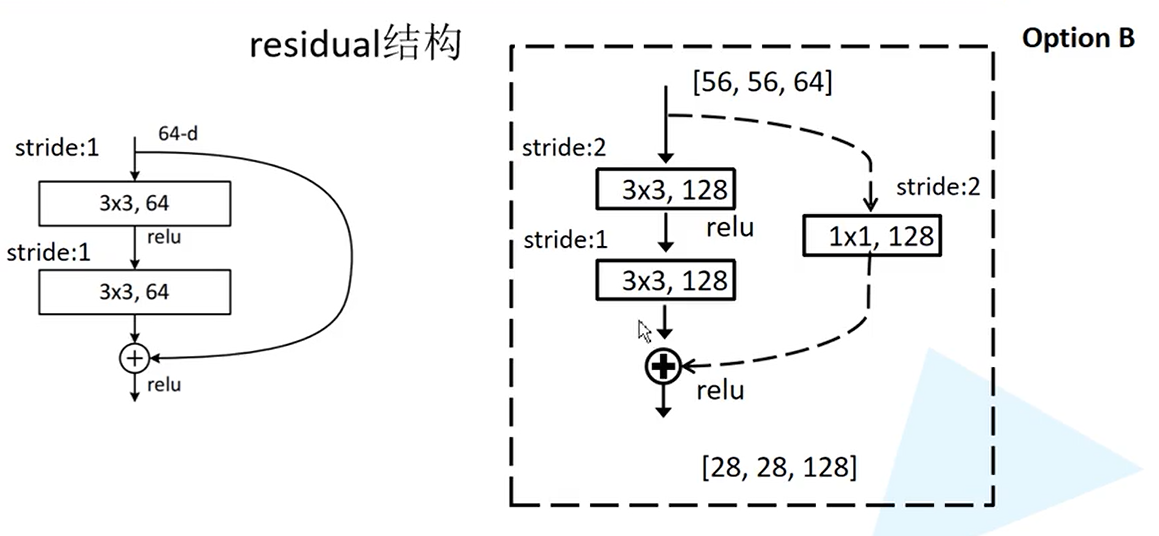
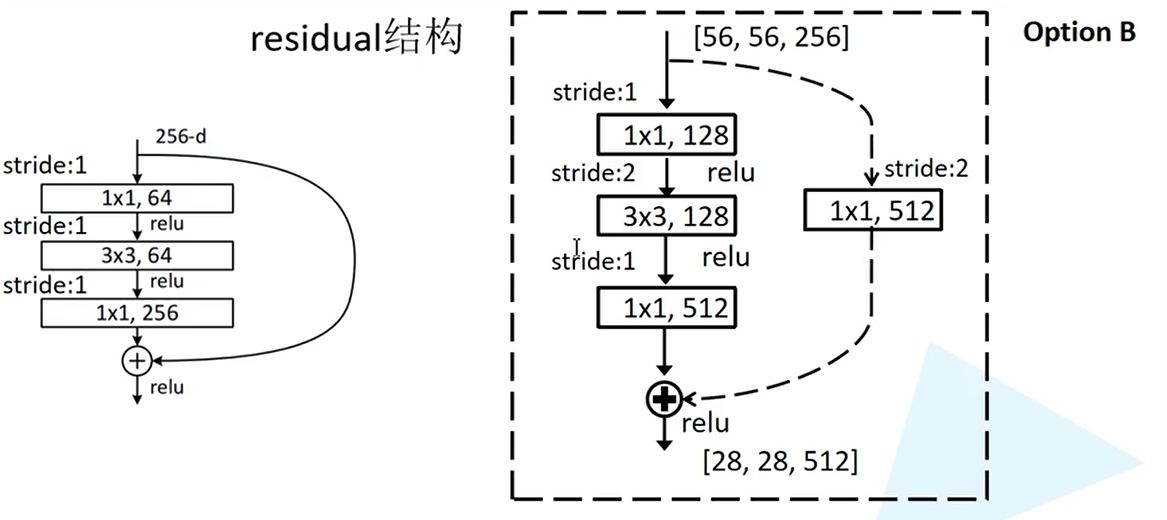
residual结构
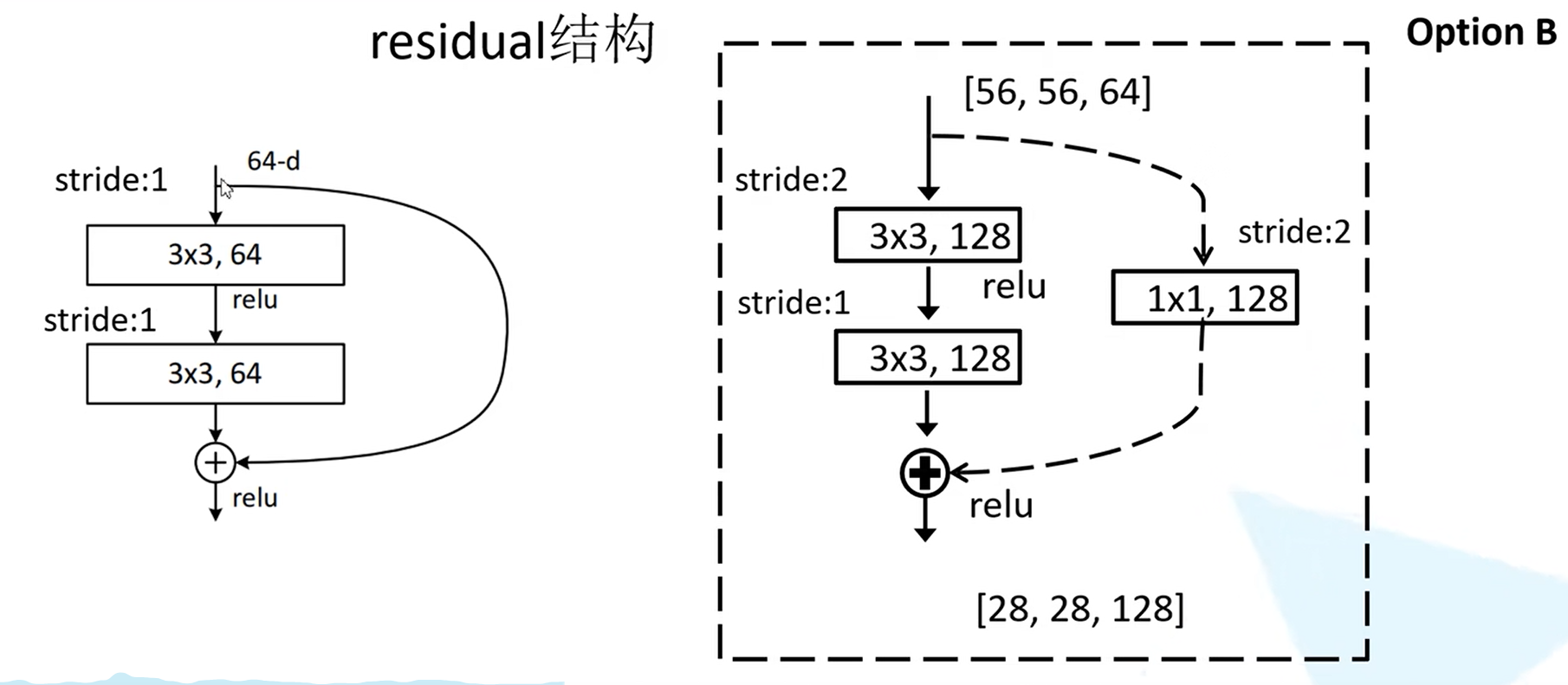
ResNet提出了一种残差网络结构,使得更深层次的网络能够有更好的表现。通过主分支与侧分支的特征矩阵进行相加得到新的特征矩阵后,再通过Relu激活函数。需要注意的是,要想使两个分支的特征矩阵能够相加,必须要保证两个特征矩阵的大小相同。
Batch Normalization
BatchNormalization的目的是使训练的一个Batch的Feature Map满足均值为0,方差为1的分布。该方法是由google在2015年提出的,目的是加速网络收敛并提升准确率。
随着网络的深度增加,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,这样继续下去就会导致梯度消失。BN就是通过方法将该层特征值分布重新拉回标准正态分布,特征值将落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。

在使用Batch Normalization时,Batch越大,计算出的均值和方差越接近整个训练集,因此应当尽量将Batch设置大一些。
网络搭建
ResNet网络中有两种残差结构,一种是直接将输入与输出相加的结构,对应的实线残差结构;另一种是在主分支中改变了特征图的尺寸,在侧分支中也需要将输入进行相应的尺寸维度的变换,保证能够将两个分支进行相加。
BasicBlock
对于18层和34层的ResNet,采用下图类型的残差结构,主分支上采用了两个3x3的卷积层。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
|
Bottleneck
对于更深的ResNet,主分支只采用了1个3x3卷积层,两个1x1的卷积层实际上是用于改变图像维度。这种做法可以减少网络参数的个数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
|
ResNet
初始化
block参数是用于传入之前定义的BasicBlock以及Bottleneck类,主要是指定残差结构类型。blocks_num是一个列表,用来定义各层的残差块数量。include_top用于配置网络是否包含全连接层。
初始化时主要是定义各层结构和生成各层残差结构,当网络包含全连接层时,首先通过一个自适应的平均池化下采样操作后再进行全连接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
生成残差结构
ResNet中定义了_make_layer函数用于生成残差层结构。
首先需要判断是否生成下采样操作。当stride !=1时,输出特征的尺寸必然会发生变化,当self.in_channel != channel * block.expansion时,输出特征矩阵的维度发生变化,因此在这两种情况下需要在分支结构上定义下采样操作,从而保证主干网络与残差分支可以进行相加。
接下来就需要生成残差块结构,由于只有第一层中可能出现带有下采样的残差结构,即上图的虚线结构,因此,第一层结构需要单独进行配置,之后的残差块的残差分支都是输入与输出直连,即上图的实现结构,因此只需要循环生成即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
|
forward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
|
迁移学习
迁移学习是利用以往任务中学出的“知识”,比如数据特征、模型参数等,来辅助新领域中的学习过程。其原理是:神经网络在学习过程中,浅层网络能够学习到数据集中较为初级的特征,这些学习的结果在类似的任务中可能同样适用。因此迁移学习往往能使模型较快的收敛且获得较好的效果。
常见的迁移学习方式:
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入全中后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层b
在训练中使用预训练模型
在训练中使用预训练模型首先需要加载模型参数
1
| net.load_state_dict(torch.load(model_weight_path))
|
因为原模型的训练类别是1000种,当我们加载完参数后需要对最后一层全连接做调整,将输出类别修改与当前任务相同。
1
2
| in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 5)
|
之后的训练过程与普通训练过程相同。这样就完成的预训练模型的加载。
笔记根据B站UP主霹雳吧啦Wz视频合集【深度学习-图像分类篇章】学习整理



