
利用Python requests库爬取教务系统
在大二的时候感觉学校的教务系统特别落后,成绩查询,课表查看这些功能使用起来特别麻烦。正好那个时候学校官方助手公众号特别不稳定,所以就有了自己动手的想法。这篇博客的所写的内容都是我自己在摸索过程中的一些经验总结。
要想实现爬取教务内容,必须要解决的一个问题就是如何登录。我们学校教务系统必须要通过校外vpn访问,所以就需要解决两次登陆问题。
易瑞授权访问系统登录
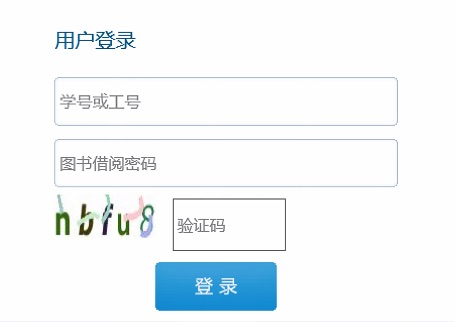
我们学校用的是易瑞授权访问系统,开始的时候登录不需要验证码的,后来学校把所有的账号全部重置,并且加上了验证码,这个验证码也成为了最头疼的地方。
验证码
解决思路是首先需要找到验证码的url,首先请求验证码,然后将请求验证码时的cookie保存,当输入完验证码后,携带请求头,请求体以及请求验证码时返回的cookie再次请求登录即可完成登录,当然,也我们可以使用requests中的session实现。
首先通过F12开发者工具查看有关验证码的请求信息
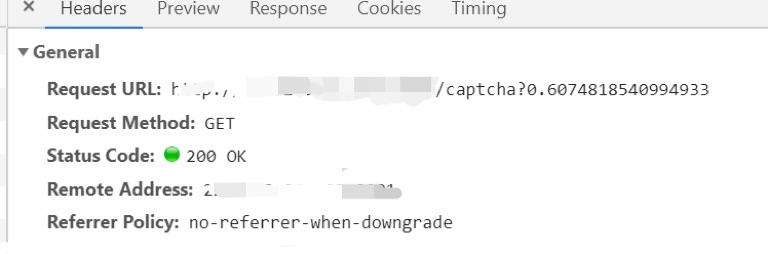
我们可以看到验证码请求的url,然后我们尝试请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import requests
from PIL import Image
session = requests.session()
imgurl = 'http://xxx.xxx.xxx.xxx/captcha'
img = session.get(imgurl)
#利用PIL库读取验证码并显示
with open('captcha.png', 'wb') as f:
f.write(img.content)
img = Image.open("captcha.png")
img.show()
|
运行后验证码成功显示出来就可以进行下一步登录了
登录
通过F12开发者工具查看登录提交时的url及数据。
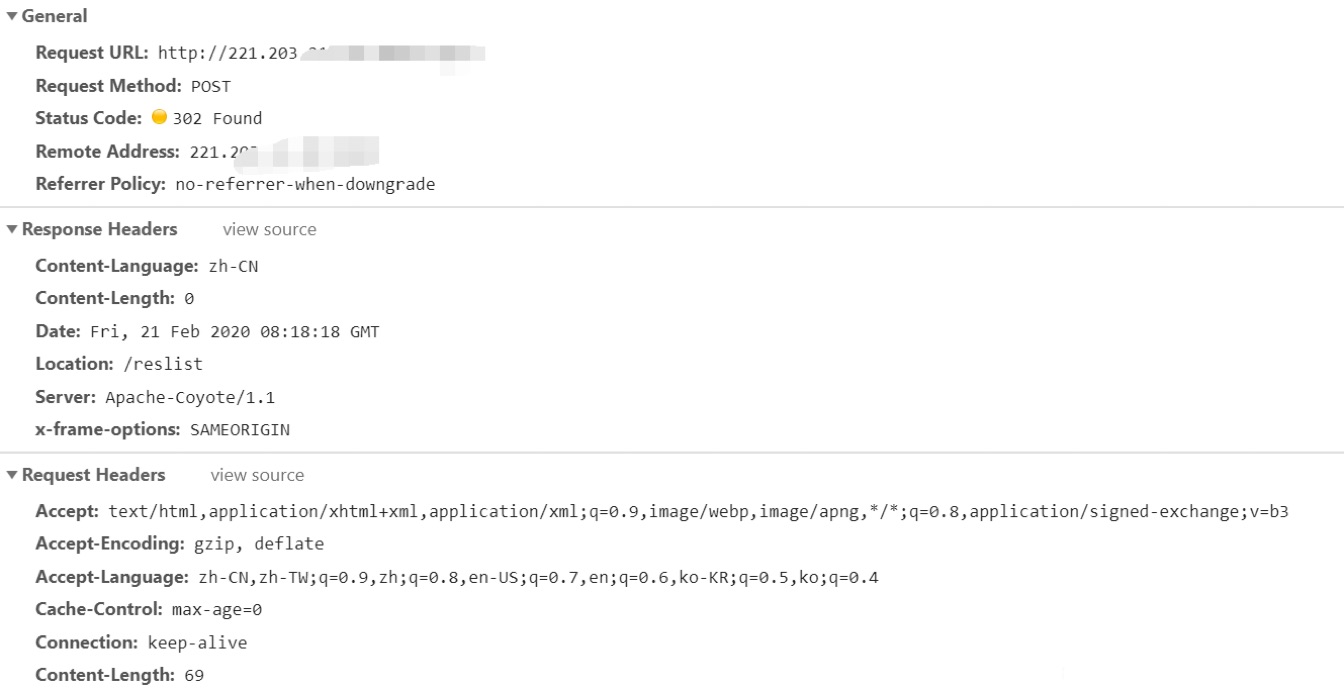
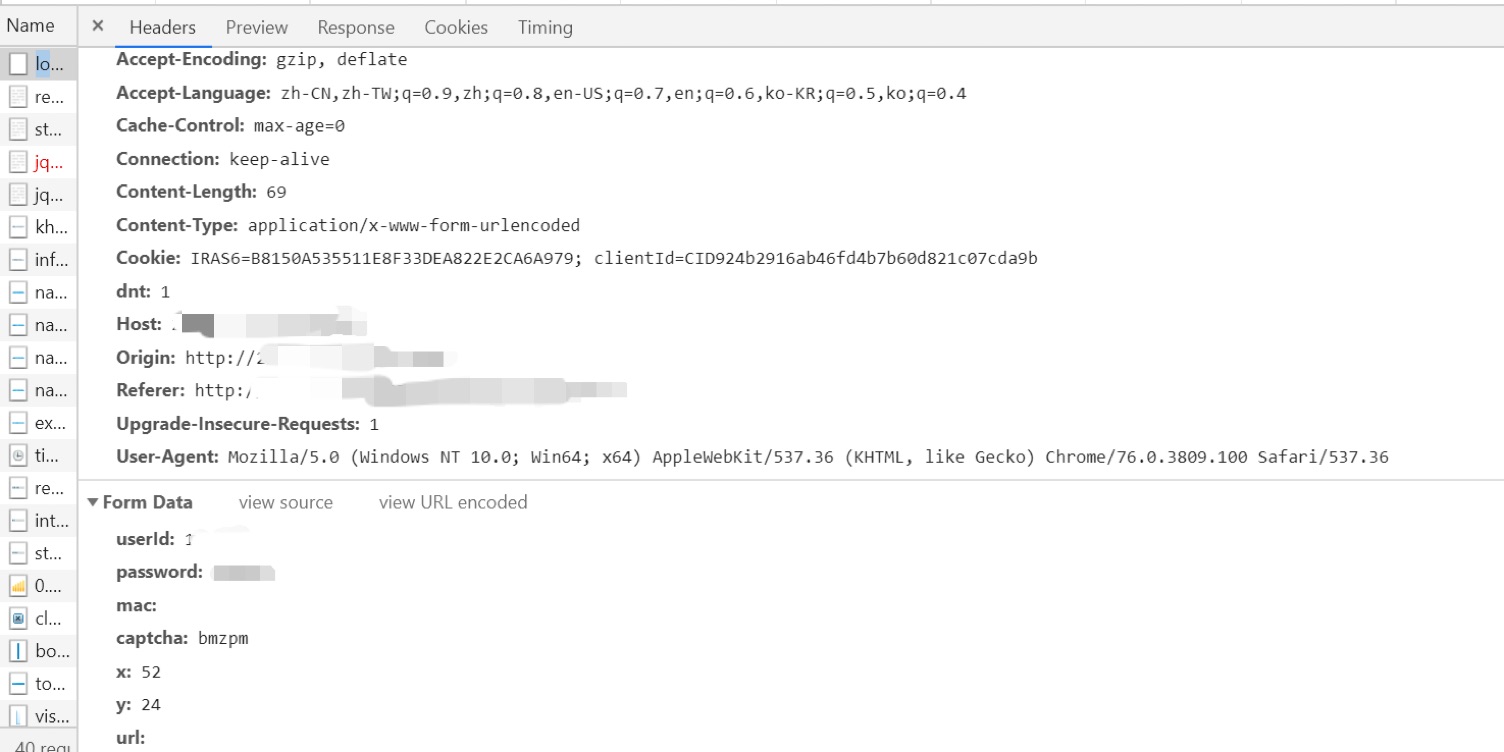
我们在这里可以看到登录的请求头请求体相应头响应体这些信息,分析出上图中的request url 就是我们数据要提交的地址,以及需要提交的数据formdata。
首先我们来解决这一部分的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
header = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)'
}
captcha = input('验证码:') #从键盘获取输入
paylosd = {
'userId':xxxxxxxx, #学号
'password':xxxxxxx, #密码
'captcha':xxxxx, #输入的验证码
'x':52,
'y':25
}
url = 'http://xxx.xxx.xxx.xxx'
session.post(url,headers = header,data = payload)
res = session.get('http://xxx.xxx.xxx.xxx:8080/reslist')#登录后才能跳转成功
print(res.text)#输出网页源码查看是否登录成功
|
请求一个登录后可以成功跳转的url,输出源码验证是否登录成功。
将以上两段代码合并后运行
urp综合教务系统登录
有了刚才的经验,接下来就容易多了。解决思路大致相同,首先请求验证码,输入验证码后,构造请求头、请求体,然后post到相应的url完成登录。相应的请求头等信息可通过浏览器中的开发者工具自行分析,在这就不再赘述。
参考代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| import requests
from PIL import Image
try:
session = requests.session()
url = 'http://xxx.xxx.xxx.xxx/captcha'
img = session.get(url)
cookies = requests.utils.dict_from_cookiejar(session.cookies) #取出session中的cookie
# 利用PIL库读取验证码并显示
with open('captcha.png', 'wb') as f:
f.write(img.content)
img = Image.open("captcha.png")
img.show()
img.close()
captcha = input('验证码:')
header = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)'
}
payload = {
'userId': 'xxxxxxx',
'password': 'xxxxxxx',
'captcha': captcha,
'x': 52,
'y': 25
}
url = 'http://xxx.xxx.xxx.xxx/login'
session.post(url, headers=header, data=payload)
imgurl = 'http://xxx.xxx.xxx.xxx/validateCodeAction.do'
img = session.get(imgurl,cookies=cookies)
# 利用PIL库读取验证码并显示
with open('captcha.jpg', 'wb') as f:
f.write(img.content)
img = Image.open("captcha.jpg")
img.show()
header = {
'Connection': 'keep-alive',
'Origin': 'http://xxx.xxx.xxx.xxx',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'Referer': 'http://xxx.xxx.xxx.xxx/'
}
yzm = input('验证码:') # 从键盘获取输入
url = 'http://xxx.xxx.xxx.xxx/loginAction.do'
payload = {
'zjh': "xxxxxxxx", # 学号
'mm': "xxxxxxx", # 密码
'v_yzm': yzm # 验证码
}
# 登录
res = session.post(url, headers=header, data=payload,cookies=cookies)
print(res.text)
session.get('http://xxx.xxx.xxx.xxx/logout') # 外网访问注销
except Exception as e:
print(e)
session.get('http://xxx.xxx.xxx.xxx/logout') # 外网访问注销
|
我在使用session登陆的时候,发现教务系统登录不上去,起初我以为是请求头的问题,但后来尝试了几次,依然登录不上去。后来我改用requests+cookie登录的时候发现了一个问题,在外网访问登录请求验证码的时候的cookie是IRAS6字段,当外网访问登录成功后变成了IRAS6、clientId两个字段,当我单独用IRAS6做cookie登录教务系统的时候就可以登录成功,当我用IRAS6、clientId这两个都做为cookie的字段时登录就失败。这和我在抓包过程中看到的是不同的,这也是我不明白的地方。
另外,由于我们学校的外网访问系统的限制,在不注销登录的前提下,每个账号最多可以登录两次。所以我加了一条注销请求,并做了异常处理,保证在多次请求时不会出现账号被限制的情况。

